Stable Diffusion web UI チェックポイントモデルの使い方

Stable Diffusionモデルについて
Stable Diffusionモデル、またはチェックポイントモデルは、特定のスタイルの画像を生成するために事前にトレーニングされたデータです。
モデルが生成する画像の種類は、トレーニング画像に依存します。トレーニングデータに猫の画像が一切含まれていなければ、モデルは猫の画像を生成することはできません。同様に、もしモデルを猫の画像のみで訓練した場合、それは猫の画像のみを生成するでしょう。


MSI GeForce RTX 3050 LP 6G OC PCIe4.0 ロープロファイルサイズ 補助電源不要 デュアルファン搭載 グラフィックスボード VD8790
ASIN:B0CTJZCJH1

玄人志向 NVIDIA GeForce RTX3060 搭載 グラフィックボード GDDR6 12GB GALAKURO GAMINGシリーズ 【国内正規代理店品】 GG-RTX3060-E12GB/OC/DF
ASIN:B08XMC4QJ1


玄人志向 NVIDIA RTX4060 搭載 グラフィックボード GDDR6 8GB【国内正規代理店品】 GK-RTX4060-E8GB/WHITE/DF2
ASIN:B0DPPC7NHX

【国内正規品】NVIDIA RTX A400 4GB GDDR6 Ampere アーキテクチャ グラフィックスボード ENQRA400-4GER ELSA エルザ
ASIN:B0DFXNDR4S


GIGABYTE NVIDIA GeForce RTX4060搭載 グラフィックボード GDDR6 8GB【国内正規代理店品】 GV-N4060OC-8GL
ASIN:B0CG69PH11

玄人志向 NVIDIA GeForce RTX2060 搭載 グラフィックボード GDDR6 12GB GALAKURO GAMINGモデル GG-RTX2060-E12GB/DF ブラック
ASIN:B09Q66CLY2

ASUS Dual GeForce RTX 3050 OC Edition 6GB GDDR6 ビデオカード/DUAL-RTX3050-O6G 国内正規流通品
ASIN:B0CVQMD2DF
モデルを探すには🔗Cibitaiや🔗Hugging Face等でお好みのモデルを探します。
Civitai

CibitaiはAIアートの発展とユーザーの交流を目的に2022年より始まったサービスで、Stable Diffusionで利用できるモデルをダウンロードするプラットフォームです。モデルのダウンロード以外にもAIアートや記事の投稿、オンサイトでの画像生成・Loraの学習等のサービスが提供されています。ホームページもサムネイル付きの一覧で見やすくなっており初心者の方にはコチラをおススメします。
Cibitai-モデルのダウンロード方法
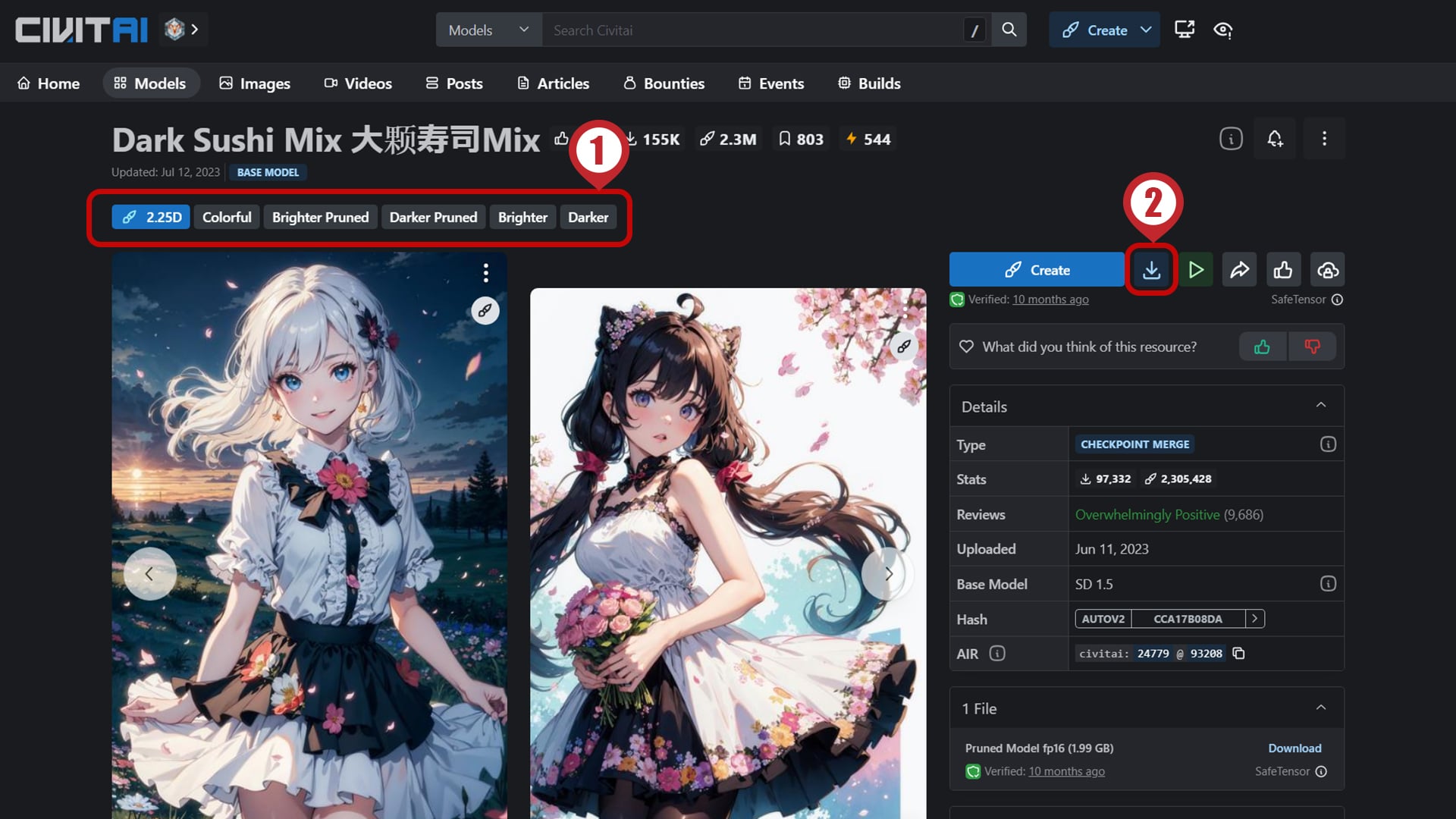
Aitasai氏のDark Sushi Mixモデルを参考に説明します。※このモデルは後ほど詳しく紹介します。
Hugging Face (Hugging Face Hub)

Hugging Face (Hugging Face Hub)はHugging Face, Inc.が2022年より始めたGitベースのホスティングサービスです。モデルのダウンロード以外にもテキスト・画像や音楽のデータセットが共有されています。ホームページはCivitaiと比べるとより専門的になっており初心者の方にはあまり向いていません。
Hugging Face-モデルのダウンロード方法

ここでは🔗Vsukiyaki氏の🔗ShiratakiMixを例として説明します。
.ckptと.safetensorsファイルがある場合は.safetensorsの方をダウンロードしましょう。
モデルファイルにはckptとsafetensorsと言うファイルが存在します。もともとモデルファイルはckpt形式で共有されていましたがckptファイルには悪意のあるコードを埋め込めるという問題がありました。そこでHugging Faceがより安全で早いsafetensors開発しました。すべてのckptが危険という訳ではありませんがとくに理由がない場合はsafetensorsを使いましょう。
チェックポイントモデル紹介
参考までにこの記事のトップ画像の生成に使ったのチェックポイントモデルです。
- 作者:🔗Aitasai
- ダウンロード:1.99 GB
- アップロード:2023/6/11
- ファイル形式:SafeTensor
- Base Model:SD 1.5
- 推奨VAE:🔗vae-ft-mse-840000-ema ※この記事ではVAEの使い方は説明していません。
- Hires. Fix推奨
また、下記の記事ではオススメチェックポイントを紹介しています。


チェックポイントモデルのインストール方法
チェックポイントモデルをStable Diffusion web UIで使用するにはダウンロードしてきたdarkSushiMixMix_225D.safetensorsファイルを\stable-diffusion-webui\models\Stable-diffusionフォルダーに移動します。

ブラウザに戻り左上のチェックポイントモデルの選択タブの横の「🔄」ボタンを押します。
更新が完了するとタブより先ほどフォルダーに移動したチェックポイントモデルが表示されるので選択して読み込みます。
チェックポイントモデルの使い方
試しに下記のプロンプトをペーストしてみましょう。
(ultra art illustrated style, masterpiece:1.3), ultra detailed, dutch_angle,
1girl, beautiful face,
(medival, mage:1.1), hill_side, blue_sky,horizonネガティブプロンプトにも下記のプロンプトをペーストしてみましょう。
(worst quality:2.0), (low quality:2.0), (normal quality:2.0), lowres設定は以下の通り入力して「Generate」ボタンを押してください。
- Sampling method: DPM++ SDE
- Schedule type: Karras
- Sampling steps: 35
- Width: 768
- Height: 512
- CFG Scale: 5
- Seed: 2454522269
- Batch count: 1
- Batch size: 1

ファンタジー風の女の子が生成されたと思いますが、解像度が768×512なので少しラフな感じがしますよね。そこで「Hires. Fix」を使いさらにデティールを増やしてみましょう。
「Hires. Fix」のチェックボックスをオフのままにして設定を下記のようにします。
- Upscaler:R-ESRGAN 4x+
- Hires steps:15
- Denoising strength:0.3
- Upscale by:2
- Resize width to:0
- Resize height to:0
「Generate」ボタンを押してお気に入りの画像が出てきたらプレビュー画像の下に並んでいる一番右側の✨ボタンを押すとその画像にHires. Fixを適応してくれます。

ベースモデルについて
「ベースモデル」には、SD1.5とSDXLの2つの主要なバージョンがあります。以下にそれぞれの特徴を説明します。
SD1.5
- 学習ベースの解像度:512×512ドット
- テキストエンコーダー:Open AI CLIP ViT-L/14
- 主な特徴:SD1.5は、比較的低い解像度で画像生成を行います。プロンプトの記述方法が直感的であり、扱いやすい一方で、生成される画像の細部には限界があります。
SDXL
- 学習ベースの解像度:1,024×1,024ドット
- テキストエンコーダー:OpenClip model (ViT-G/14) & OpenAI proprietary CLIP ViT-L.
-
主な特徴:
- 高いプロンプトの理解力:テキストエンコーダーにOpenClip modelが加えられたことによりさらにプロンプトの理解力が向上。
- 高い処理能力:より大きく複雑な画像生成タスクに対応できます。
- 高品質の画像:リアリズムとディテールのレベルが向上しており、非常に高解像度の画像を生成できます。
- 速度:以前のモデルよりも高速に作業し、画質を損なうことなく画像生成にかかる時間を短縮します。
PrunedとFullとEMA-onlyモデルの違いについて
- Pruned Model:モデル学習の完了後にプルーニングされ、冗長な部分を取り除いた軽量モデル。リソースが限られた環境や高速な生成が必要な場合に使います。
- Full Model:軽量化される前のモデル。学習したすべての情報を持っているため精度に優れています。
- EMA-only Model:Pruned Modelと似ていますが、学習中の最終数ステップにノイズの平滑化を適応させているモデル。データが軽量化された上に精度の安定した画像生成ができます。
Fp16とFp32について
モデルデータにはFp16またはFp32と表示されています。「Fp」はFloating point(浮動小数点)の略でFp16はメモリ使用量を削減し、計算速度を向上させることができるため、リソースが限られている環境や、高速な処理が求められるアプリケーションで利用されます。一方、Fp32はより高い精度が必要な場合や、大規模なデータセットを扱う場合に適しています。
チェックポイントモデルデータは非常に大きなファイルになり、モデルデータを色々と試しているとストレージを圧迫します。とくにこだわりがない場合は、PlunedのFp16をダウンロードしましょう。
まとめ
この記事では、Stable DiffusionのWeb UIにおけるチェックポイントモデルの使い方を詳しく解説しました。Stable Diffusionモデルを使用することで、生成される画像のスタイルを効果的にコントロールできます。また、モデルは定期的にアップデートされており、新しいバージョンが追加されているため、常に最新の技術を活用できます。チェックポイント以外にも、Lola、Textual inversions (embedding)、VAE、Hypernetworksなど、さまざまな機能が存在しますが、それらについては別の機会に詳しく紹介したいと思います。

ASUS ゲーミングデスクトップPC ROG Strix G13CHR GeForce RTX 4060 インテル Core i5 14400F メモリ32GB SSD1TB Windows11 動画編集 エクストリームダークグレー G13CHR-51440F158W/A
ASIN:B08H21HKTX

【Amazon.co.jp限定】 ASUS ゲーミングノートPC TUF Gaming A15 FA507NVR 15.6型 RTX 4060 Ryzen 7 7435HS メモリ16GB SSD1TB リフレッシュレート144Hz RGB イルミネートキーボード Windows 11 動画編集 Xbox Game Pass 3ヶ月利用権付き FA507NVR-R74R4060T
ASIN:B0CWVCYZC5

【Amazon.co.jp限定】【Core i7 & RTX 4060搭載・薄型軽量スケルトン】MSIゲーミングノートPC Cyborg15 1.98kg Corei7 RTX4060/15.6インチ FHD/144Hz/16GB/512GB/Windows 11/Cyborg-15-A13VFK-1002JP
ASIN:B0CTKCP81B

mouse 【RTX5090搭載 / 3年保証】 ゲーミングPC デスクトップPC G TUNE FZ (Core Ultra 9 プロセッサー 285K RTX 5090 128GB メモリ 2TB SSD 無線LAN 水冷CPUクーラー 動画編集 ゲーム) FZI9G90GB12SKW104AZ
ASIN:B0F3XFJG7K

UNFINITY ゲーミングPC UNF4060-V3EX(i5-12400F / 32GB / RTX4060 / NVMe M.2 SSD 1TB / Windows11 home
ASIN:B0F14223F6

【最新第13世代 Core i9 HX & RTX 4090搭載・ウルトラハイエンド】MSIゲーミングノートPC RaiderGE78HX i9HX RTX4090/17型 WQXGA/240Hz/32GB/2TB/Windows11/Raider-GE78HX-13VI-2803JP
ASIN:B0BVBM5T8F

ガレリア ゲーミングPC GALLERIA RM7R-R46 RTX 4060 Ryzen 7 5700X メモリ32GB SSD1TB Windows11 動画編集 2年保証 ガンメタリック
ASIN:B0DVGTSGPM

Corsair ONE i500 ゲーミングPC – 液体冷却インテル Core i9-14900F CPU – NVIDIA GeForce RTX 4070 Super GPU – 32GB Vengeance DDR5メモリ – 1TB M.2 SSD – ウッドダーク
ASIN:B0DVGR26WW

ゲーミングPC デスクトップ パソコン ドスパラ Diginnos Core i7-12700 - RTX 3060 12G - 32GBメモリ - SSD2.0TB - Windows 11 - THIRDWAVE ゲームPC VR 生成AI (整備済み品)
ASIN:B0DSS2DHFC

Dell ノートパソコン Alienware m18 R2 18インチ Intel Core i7-14700HX GeForce RTX 4070 メモリ16GB SSD2TB Windows 11 ダークメタリックムーン NAM9H28A-EHLB
ASIN:B0D2KJT7DL