Stable Diffusion web UIの基本的な使い方 Image-to-image編

- img2imgのインターフェイスの説明
- img2imgのモードについて
- Canvasの使い方
- img2imgのResize modeについて
- Denoising strengthについて
- img2imgのSoft inpaintingについて
- img2imgの色調補正について
- インプット画像の透明部について
- Sketchモードのキャンバスサイズについて
- インペイント モードのOnly maskedとターゲット サイズについて
- img2imgモードの使用例
- Sketchモードの使用例
- Inpaintモードの使用例
- Inpaint Sketchモードの使用例
- Inpaint uploadモードの使用例
- Batchモードの使用例
- まとめ
今回はA1111 Stable Diffusion web UIの「Image to image (img2img)」の基本的な使い方を説明していきたいと思います。img2imgを使えば入力したイラストとプロンプトを使って新たなイラストを生成します。用途としてはラフがから生成AIを使って清書したり、生成されたイラストを入力して手や顔の修正や不要部分の取り除いたりできます。
img2imgのインターフェイスの説明
各エリアについて


チェックポイント・プロンプトエリアについて

生成ボタン エリアについて

プレビュー エリアについて説明

ページ切り替えエリアについて説明

イメージインプット エリアについて説明

生成パラメーター エリアについて説明

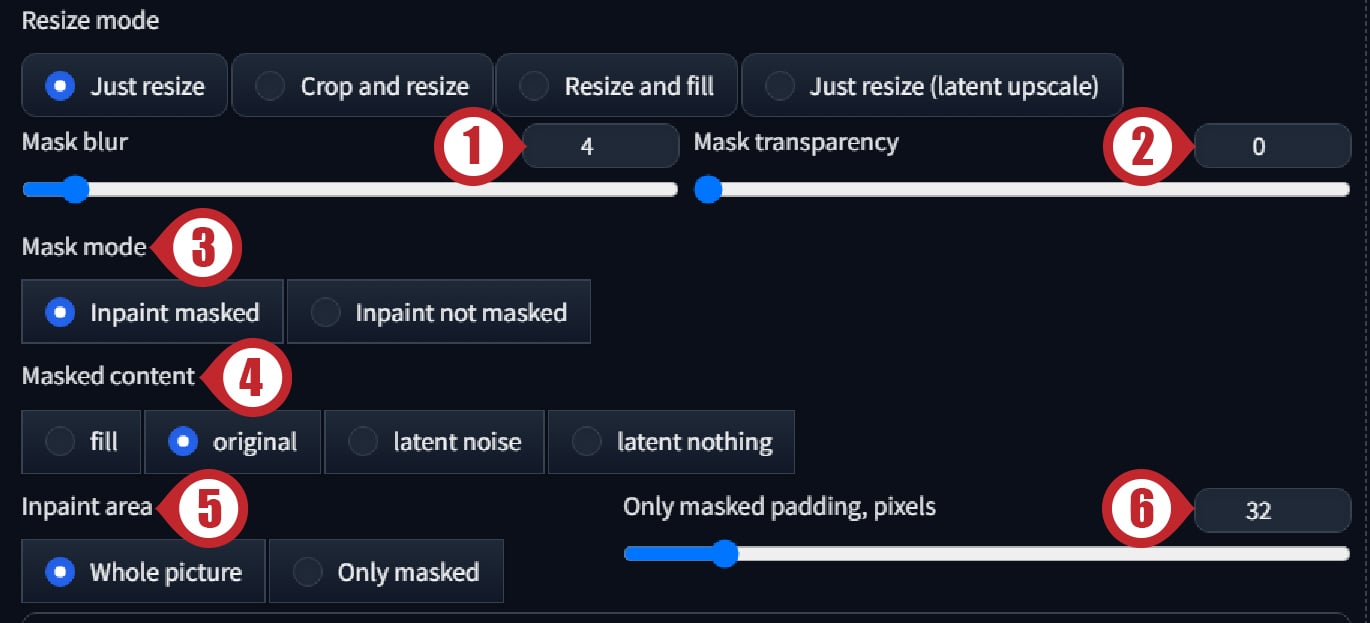
- Inpaint masked:マスクの選択範囲内をインペイントします。
- Inpaint not masked:マスクの選択範囲以外をインペイントします。
- fill:インプット画像のマスク範囲内の平均色で塗りつぶします。
- original:インプット画像をそのまま使います。
- latent noise:マスク範囲内をSeedに基づいたノイズで塗りつぶします。対象物をマスクして背景を書き換えるときに使えます。CGFは
1をオススメします。 - latent nothing:マスク範囲内の平均色で塗りつぶします。対象物をマスクして背景を書き換えるときに使えます。CGFは
0.8以上をオススメします。
- Whole picture:マスク範囲外も含めて全体にインペイントを適応します。
- Only masked:マスク範囲内のみにインペイントを適応します。
img2imgのモードについて
A1111 Stable Diffusion web UIのImage to imageには6つのモードがあります。この記事の後半で使用例と共に詳しく説明しているのでここでは簡単に説明します。
- img2img:デフォルトのモード。インプット画像に近い構図でイラストを生成します。
- Sketch:単色の背景色の画像をアップロードしてキャンバスにスケッチを描き、それを元にイラストを生成します。
- Inpaint:インプットされたイラストにマスクを指定し、それを元にイラストを生成します。
- Inpaint sketch:Inpaintモードと似ていますが、違いはInpaintはマスク指定しかできませんが、Inpaint sketchはスケッチ部分がマスクにもなり生成のコントロールができます。
- Inpaint upload:インプット画像とマスク画像を読み込んで、それを元にイラストを生成します。Photoshop等のソフトウェアで作ったイラストをインペイントしたい時に使います。
- Batch:複数のインプット画像を一度にimg2imgプロセスを処理できます。
Canvasの使い方
Canvasはインプット画像にスケッチを書いたり、マスクを指定する為の機能です。マウスを使ってブラシで描きます。

- Alt + マウス ホイール:キャンバスをズーム イン・ズーム アウトします。
- Ctrl + マウス ホイール:ブラシの大きさを設定します。
- Rキー:キャンバスのズームをリセットします。
- Sキー:キャンバスをフルスクリーン モードにします。RキーかSキーをもう一度押せばノーマル モードになります。
- Fキー:Fキーを押しながらマウスのドラッグでキャンバスを移動できます。

- Undoボタン:直前のブラシをキャンセルします。
- Clearボタン:キャンバスのブラシをすべて削除します。
- Removeボタン:インプット画像を削除します。
- Use brushボタン:ブラシの大きさを設定します。
- Select brush colorボタン:ブラシの色を設定します。(SketchとInpaint sketchのみ)
img2imgのResize modeについて
Resize modeで拡大縮小時の設定を変えることができます。
- Just Resize:縦横比は維持されませんので指定先のサイズの縦横比が違う場合は、画像が伸び縮みします。
- Crop & Resize:縦横比は維持されるのではみ出した部分は削除されます。
- Resize & Fill:縦横比を維持したまま、指定先のサイズに収まるように拡大縮小します。余った部分はインプット画像の端の色で塗りつぶされます。
- Just Resize (Latent Upscale):Just Resizeと同じですが拡大縮小にLatent Upscaleを使います。
Denoising strengthについて

Denoising strengthはインプット画像にどれだけ近い画像を生成するかの値になります。txt2imgのHires. fixにあるDenoising strengthと同じパラメーターになります。上記のサンプルはblack chairからwhite chairにプロンプトを変更してimg2imgモードで生成しています。
- 0.0:変化なし
- 0.35:少しの変化
- 0.75:かなりの変化
- 1.0:大部分の変化
img2imgのSoft inpaintingについて
Soft inpaintingはInpaintモードを使用時にマスクと背景との境を違和感なくブレンドしてくれます。Musk blurを高めに設定することを推奨します。例 Mask blur: 20
Soft inpaintingのパラメーターについて

- Schedule bias:インプット画像の維持をどのステップのタイミングから適応するかのバイアスになります。デフォルトは1です。1より大きいくすればサンプリングの初期段階から維持してくれます。しかし高すぎれば書き足し部分も少なくなります。逆に小さくすればサンプリングの後の方から維持するのでインプット画像との境が目立ってきます。
- Preservation strength:インプット画像の維持の強度になります。高いほどインプット画像を維持してくれます。
- Transition contrast boost:インプット画像とインペイントとの差を調節します。デフォルトは4になります。数字が高いほど境目がシャープになります。逆に低い場合はインペイント対象物が小さくなるが、境目がスムーズになります。
- Mask influence:マスクの影響度になります。数字が多きい程マスクの影響度が上がります。0の場合はマスクを無視しします。※v1.10.1でテストしたところこの数値を変えても結果は変わりませんでした。
- Difference threshold:インプット画像との差分のしきい値になります。デフォルトは
0.5になります。大きくするほどインペイント部分が透明になっていきます。 - Difference contrast:インプット画像とインペイント部分の差異を調節します。デフォルトは
2になります。小さくすると透明になっていきます。
Soft inpaintingの使用例
サンプルではSoft inpaintingをCFGとサイズ以外はデフォルト値で適応しています。Soft inpaintingを使わない場合はマスクの境界が目立っていますが、Soft inpaintingを使った方は境界がほとんど判らなくなっています。




img2imgの色調補正について

img2imgを使っている時に生成イラストの色味が変わる場合があります。A1111 WebUIのカラー コレクション機能を使いましょう。
- Settingsタブで設定ページを開きます。
- 左側の一覧よりStable Diffusionの中にあるimg2imgを選択します。
- 「Apply color correction to img2img results to match original colors.」と書かれているチェックボックスをオンにします。
- Apply settingsボタンを押して適応させます。
以上で設定は完了ですが、頻繁に切り替える場合は以下の方法でQuicksettings listに追加しましょう。
- 一覧よりUser InterfaceにあるUser Interfaceを選択します。
- Quicksettings listに
img2img_color_correctionと入力して一覧より選択します。 - Apply settingsボタンを押して適応させます。
- Reload UIボタンで再起動します。起動後UIの上部にチェックボックスが出ていたら設定完了です。
インプット画像の透明部について
インプット画像がPNGなどで透明部分がある場合デフォルトでは白として使われます。これは設定にて別の色に変えることができます。
- Settingsタブで設定ページを開きます。
- 左側の一覧よりStable Diffusionの中にあるimg2imgを選択します。
- 「With img2img, fill transparent parts of the input image with this color.」と書かれている下にある色を希望する色に変更します。
- Apply settingsボタンを押して適応させます。
Sketchモードのキャンバスサイズについて
Sketchモードのキャンバスはディスプレイのカスタム スケール(拡大/縮小)設定に影響されるのでご注意ください。Windowsでディスプレイのカスタム スケールを100%以外の設定にしている場合はキャンバスの大きさが影響されます。
たとえばディスプレイのカスタム スケールが150%の設定で、キャンバスに512 x 512ピクセルを読み込んだ場合、キャンバスの大きさは1.5倍の768 x 768になってしまいます。
Resize toで目的の解像度をしてする場合は問題ないのですが、Resize byでScale 1の等倍で設定した場合、カスタム スケール影響で768 x 768の解像度で生成されてしまいます。このような場合はディスプレイのカスタム スケール設定を100%に切り変えて作業をしましょう。
インペイント モードのOnly maskedとターゲット サイズについて

これはDarkStooM氏の🔗Gistで書かれたいたことですが、Only maskedモードを使用時にマスク範囲内がターゲット サイズにUpscalerモデルを使って拡大されてからインペイントを適応しているのでOnly maskedモードの方がディテールが出るようです。上記の比較画像は512×512で生成し、 目の部分のみにインペイント マスクを指定して等倍で生成しています。
Upscalerモデルはデフォルトでは選択できないのですが、下記の方法で選択できるようになります。
- Settingsタブで設定ページを開きます。
- 左側の一覧よりUser InterfaceにあるUser Interfaceを選択します。
- Quicksettings listに
upscaler_for_img2imgと入力して一覧より選択します。 - Apply settingsボタンを押して適応させます。
- Reload UIボタンで再起動します。起動後UIの上部にUpscaler for img2imgが出ていたら設定完了です。
img2imgモードの使用例
img2imgモードは、インプットされた画像を元に生成します。生成画像の構図はDenoiseの値にもよりますが元の画像と同じになります。
写真画像をインプットしてイラストを生成してみましょう。

インプット画像はUnsplashからお借りした🔗ロンドンの街角の写真になります。この写真をキャンバスにドラッグもしくはクリックして読み込みます。
今回使用するSD1.5モデル(darkSushiMixMix_225D)はDanbooruスタイルが好ましいので生成ボタン エリアのプロンプト生成ボタン(DeepBooru)をクリックしてプロンプトを解析しましょう。
解析が終わればプロンプトの先頭に下記のプロンプトを挿入してイラスト調にします。
(anime style:1.5), 続いてネガティブ プロンプトに下記のプロンプトを貼り付けます。イラスト調にするために(realistic:1.5)を使っています。
(realistic:1.4),worst quality, low quality, normal quality, lowresパラメーターは下記の部分を変更しましょう。
- 書き込みをしっかりとしたいのでSampling stepsを
30に設定します。 - インプット画像が1920 x 1281ピクセルなので今回使用するSD1.5モデルに対応する為にResize modeを
Crop and ResizeにしてResize toを横768 x 縦512に設定します。 - モデルのスタイルを生かしたいのでCFG Scaleを
3に変更します。 - インプット画像の構図を維持したいのでDenoising strengthを
0.5に設定します。
最後に「Generate」ボタンで生成すれば完成です。

Sketchモードの使用例
Sketchモードは、キャンバスに描かれたスケッチを元にイラストを生成します。今回は「草原に佇む巨木」を生成したいと思います。「Sketchモードのキャンバスについて」で述べた通りディスプレイのスケールには注意しましょう。
まずはスケッチモードに切り替えて希望するサイズ(今回は768 x 512)の単色画像をPhotoshopなどで作成して読み込みます。単色の色は背景色にした方が後々楽になるので今回は空の色として水色の画像をアップします。
キャンバスになんとなくで良いので草原・樹・背景の山を色を変えながらスケッチします。

スケッチが書けたらプロンプトに下記のプロンプトを貼り付けます。
big tree, plane field, mountains, blue sky, masterpiece, ultra detailed続いてネガティブ プロンプトに下記のプロンプトを貼り付けます。
worst quality, low quality, normal quality, lowresパラメーターはResize toからResise byに切り替えてScaleを1に設定します。
残りの設定はデフォルトのまま使用します。構図などをスケッチに近づけたい場合はDenoising strengthを下げてください。下げすぎるとスケッチ画になりますのでバランスの良い値を見つけましょう。
最後に「Generate」ボタンで生成すれば完成です。

Inpaintモードの使用例
Inpaintモードは、img2imgの中で一番使われているモードで、txt2imgで生成したイラストの修正できます。
まずはtxt2imgで下記の設定でイラストを生成しましょう。
プロンプト: 1girl, upper body, waving, smile, looking at viewer, medival, village, masterpiece, ultra detailed
ネガティブ プロンプト: worst quality, low quality, normal quality, lowres
Steps: 20
Sampler: DPM++ 2M
Schedule type: Karras
CFG scale: 7
Seed: 3546912850
Size: 768x512
Model: darkSushiMixMix_225D
VAE: vae-ft-mse-840000-ema-pruned.safetensors
Clip skip: 2
生成が終わればプレビュー エリアにある「img2img inpaintへ送る」ボタン(赤枠)を押してInpaintモードに切り替えます。

今回は指がおかしくなっているので修正します。一度に両手を修正しても良いのですが、大抵の場合1回の生成では満足な結果にはならないので片手づつ修正するのをオススメいします。
では、左手を修正します。小指がおかしくなっているので小指と修正後の正しい位置をマスクします。
プロンプトはtxt2imgのプロンプトが引き継がれているので、先頭に下記プロンプトを挿入します。
five fingers, パラメーターはResize toからResise byに切り替えてScaleを1に設定します。他はデフォルトのまま使用します。
「Generate」ボタンを押して、満足のいく結果が出るまで生成を続けましょう。なかなか良い結果が出ない場合はCFGの値を変更してみましょう。

結果に満足したら反対の手も修正していきたいのですが、まずはtxt2imgの時と同じ「img2img inpaintへ送る」ボタンで修正後の画像をキャンバスに読み込みます。先ほどのマスクが残っているのでクリアー ボタンで消します。
右手は薬指と小指の先がおかしいのと親指の隣に指のようなものがあるのでこれを修正します。
今回のパターンだと薬指と小指の先を別々に修正しても良いのですが、纏めて修正してみましょう。キャンバスの右手の薬指と小指の先をマスクします。

プロンプトとパラメーターは先ほどと同じで問題ありません。
結果に満足すれば再度「img2img inpaintへ送る」ボタンでキャンバスに送りましょう。
最後に親指の隣の指みたいなものを消していきましょう。

Inpaintで要素を取り除く場合はMasked contentをfillに切り替えましょう。また、CFGの高めた方が元のオブジェクトをフラットにする確率が上がります。逆に低いと近い形の別のものになる可能性が上がります。
以上のプロセスで手の修正が完了しました。使ってみてわかると思うのですが運要素がかなりあります。手のLoRAやネガティブ エンベディング等を使えば良くなる場合もあるので、なかなか良い結果が得られないときは試してみるのも有りでしょう。

Inpaint Sketchモードの使用例
Inpaint Sketchモードは、インペイントとスケッチを合わせたモードでインプット画像にスケッチで新たに要素を追加できます。「Sketchモードのキャンバスについて」で述べた通りディスプレイのスケールには注意しましょう。
ここではスケッチモードの最終結果にツリーハウスを追加してみましょう。

A1111 WebUIにはInpaint sketchに送る機能がないので生成した画像を直接ドラッグ アンド ドロップまたはファイルを指定して読み込みます。
インペイント スケッチの場合スケッチがそのままマスクにもなるので書き足す場合はまずはべた塗りでシルエットを描きその上に希望する絵のアウトラインを描いていくと上手くいくでしょう。今回はツリー ハウスを書き足したいので下記の様なスケッチになりました。

スケッチが書けたらプロンプトに下記のプロンプトを貼り付けます。今回はInpaint areaをOnly maskedで生成するので書き足し部分のみを意識してツリー ハウス以外の余計なプロンプトは使っていません。
small tree house, masterpiece, ultra detailed続いてネガティブ プロンプトに下記のプロンプトを貼り付けます。
worst quality, low quality, normal quality, lowresパラメーターは下記の部分を変更しましょう。
- 背景と馴染ますためにMask transparencyを
10に設定します。 - ディテールを出したいのでInpaint areaは
Only maskedを選択します。 - Soft inpaintingのチェックボックスを
✅にしてさらに背景になじませます。設定はデフォルトのままで問題ありません。 - 等倍で生成したいのでResize toから
Resize byに切り替えてScaleを1にします。 - できるだけスケッチに近づけたかったのでDenoising strengthを
0.5にします。
最後に「Generate」ボタンで生成すれば完成です。

Inpaint uploadモードの使用例
Inpaint uploadモードは、インプット画像とマスクをそれぞれアップロードして、インペイントできます。用途は色々ありますが、Photoshopでマスクを綺麗に作りたい場合や、3DCGソフトなどで書き出したマスク部分をインペイントする場合などに使います。
今回の例では3DCGソフトで書き出したイメージに背景を書き足してみます。
インプット画像とマスクは下記の画像を使って進めていきます。


上記の画像をそれぞれインプットとマスクに読み込ませます。
背景の為のプロンプトを下記の様に入力します。
blue sky, meadows, moutains, masterpiece, ultra detailedネガティブ プロンプトに下記のプロンプトを貼り付けます。
worst quality, low quality, normal quality, lowresパラメーターは下記の部分を変更しましょう。
- マスク範囲を背景にしたいので反転させる為にMask modeを
Inpaint not maskedにします。 - 背景はインプット画像の色を元に生成したいのでMasked contentを
originalに設定します。 - インプット画像を違和感なく自然に合成させたいのでSampling methodを
DDIM CFG++、Schedule typeをDDIMに変更します。※一覧にない場合はA1111 WebUIをv1.10以上にアップデートする必要があります。 - 背景の書き込みを良くする為にSampling stepsを
30に設定します。 - スケールは等倍で生成したいのでResize toから
Resize byに切り替えてScaleを1にします。 - インプット画像の単調な背景の影響があるのでCFG Scaleを
10に上げてプロンプトの影響力を上げます。
最後に「Generate」ボタンで生成すれば完成です。

Batchモードの使用例
Batchモードは一度に複数の画像にimg2imgを適応させたい場合に使います。あまり有効的な使い方はありませんが、纏めてスタイルを適応したい場合などに使います。
今回は先の使用例で生成した3つの画像を水彩画風スケッチに変換してみましょう。ただしこの使い方は1つ1つ修正が出来ないのであまり効率的ではありません。
ここまでの例で作った下記の画像をインプットに読み込ませます。



プロンプトを下記の様に入力します。
(water color, sketch:1.5), flat color, masterpiece, ultra detailedネガティブ プロンプトに下記のプロンプトを貼り付けます。
worst quality, low quality, normal quality, lowresパラメーターは下記の部分を変更しましょう。
- Sampling methodをimg2imgと相性の良い
DDIM CFG++、Schedule typeをDDIMに変更します。※一覧にない場合はA1111 WebUIをv1.10以上にアップデートする必要があります。 - スケールは等倍で生成したいのでResize toから
Resize byに切り替えてScaleを1にします。 - プロンプトを優先させたいのでCFGを
9に設定します。 - できるだけインプット画像の要素を残したいのでDenoising strengthを
0.3にします。
最後に「Generate」ボタンで生成すれば完成です。



まとめ
A1111 Stable Diffusion Web UIの「Image to Image (img2img)」について、基本的な使い方をご紹介しましたが、いかがでしたか?このimg2img機能は、既存のアートワークをAIでブラッシュアップしたり、シンプルなスケッチからプロ並みのイラストを作り上げたり、また生成した画像を微調整するのに非常に役立ちます。クリエイティブな作業をより効率的に進めるための有用なツールなので、ぜひ試してみてください。
最後までお読みいただきありがとうございます。
もし少しでも参考になったら、ぜひ「いいね」で応援してください!