ComfyUIの基本的な使い方 Image-to-image編

今回はComfyUIで使うImage to image(img2img)の解説をしていきたいと思います。A1111 WebUIでいうところのimg2img/inpainting/sketchモードに近いワークフローを紹介していきたいと思います。
Image2image

まずは、公式のImg2Img Examplesから見ていきましょう。
リンク先のページにあるワークフローの画像をダウンロードしてComfyUIにドラッグ アンド ドロップするか、Loadボタンより読み込んでください。
読み込みが完了したら「Load Checkpoint」ノードのckpt_nameより、お好きなモデルを読み込んでください。
ConfyUIのText2imageとの違いは「Empty Latent Image」の代わりに「Load Image」と「VAE Encode」ノードを使ってインプット画像を読み込んでいます。このワークフローではインプット画像の大きさがLatentスペースとして使われるのでモデルの許容範囲内の大きさの画像をインプットしましょう。
各モデルの生成サイズの一例- SD1.5:512x512又は768x512
- SDXL:1メガピクセル:1024x1024又は1216x832等
次に「KSampler」を見てみましょう。パラメーターの一番下にdenoiseを言う項目があります。これはインプットされた画像の要素をどこまで残すかの値になります。0.0だとインプット画像がそのまま出力され1.0だとほとんどインプット画像の要素は残りません。denoiseの値を変えて色々と試してみましょう。
公式のImg2Img Examplesを改良してみる
ここからは公式のImg2Img Examplesをもう少し実用的なimg2imgワークフローに改良してみようとおもいます。以下に組み込みたいリストを纏めました。
- インプット画像をモデルの対応スケールに合わすためにスケーラーを実装。
- インプット画像からプロンプトを解析したいのでカスタムノードの「ComfyUI WD 1.4 Tagger」と「ComfyUI-Custom-Scripts」を実装。
- Clip skipを適応させる。
- LoRAを適応させる。
- 品質向上のためネガティブ エンベディングの「EasyNegative」を実装。
- ワークフローの流れを効率的にするために「Image chooser」カスタムノードを実装。
- 生成品質が良くないのでセカンドパスを実装。
- Tiledデコードを使ってメモリーの節約。
以上の項目を実装し、写真からイラストを生成するワークフローに改良します。
カスタム ノードのインストール:
「ComfyUI WD 1.4 Tagger」と「ComfyUI-Custom-Scripts」そして「Image chooser」はカスタム ノードなので、まずはインストールする必要があります。インストール方法はComfyUI Managerを使います。別記事にて詳しく紹介しているのでそちらを参照してください。

「ComfyUI WD 1.4 Tagger」は紹介していませんが、ComfyUI ManagerのCustom Nodes ManagerでComfyUI-WD14-Taggerと検索をかけて、Authorがpythongos… (pythongosssss)となっているノードをインストールしてください。
インプット画像の調整:

「Load Image」と「VAE Encode」の間に「Upscale Image」と「RepeatImageBatch」を追加します。「Upscale Image」でインプットがモデルの許容範囲外でも使えるようにリサイズしています。
「RepeatImageBatch」は後ほど導入する「Preview Chooser」の為のノードで1回の実行で指定した枚数の低画質版を出力します。
- Upscale Image:image > upscaling > Upscale Image
- RepeatImageBatch:image > batch > RepeatImageBatch
インプット画像の解析:

「WD14 Tagger 🐍」を設置後「Load Image」のIMAGEアウトをインプットに繋ぎます。後の工程で解析したタグに別のタグが連なるのでtrailing_commaをtrueに変更します。
「WD14 Tagger 🐍」のSTRINGアウトを「String Function 🐍」のtext_bに繋ぎたいので「String Function 🐍」を右クリックしてメニューからConvert Widget Input > Convert text_b to inputで外部化します。外部化したら「WD14 Tagger 🐍」のSTRINGアウトを繋ぎます。
「String Function 🐍」のtext_aに(anime style:1.5),text_cにmasterpiece, ultra detailedと入力します。これにより解析結果のプロンプトと繋がり、ポジティブ プロンプトに送ることができます。
ポジティブ プロンプトが書いてある「CLIP Text Encode (Prompt)」の右クリック メニューよりConvert text to inputで外部化して「String Function 🐍」のSTRINGアウトを繋ぎます。
完成したプロンプトを確認したいので「Show Text 🐍」に「String Function 🐍」のSTRINGアウトアウトを繋ぎます。
- WD14 Tagger 🐍:image > WD14 Tagger 🐍
- String Function 🐍:utils > String Function 🐍
- Show Text 🐍:utils > Show Text 🐍
Clip skip / LoRAの適応:

「Load Checkpoint」のCLIPアウトに「CLIP Set Last Layer」を繋ぎ、「CLIP Set Last Layer」のCLIPアウトに「Load LoRA」も繋ぎます。「Load LoRA」のCLIPアウトは2つの「CLIP Text Encode (Prompt)」に繋いでください。そして、「Load Checkpoint」のMODELアウトは「Load LoRA」に繋ぎそこから「KSampler」に繋ぎます。
- CLIP Set Last Layer:conditioning > CLIP Set Last Layer
- Load LoRA:loaders > Load LoRA
Seedの共有化:

KSamplerノードの右クリック メニューよりConvert seed to inputでSeed値を外部化します。seedインプットの●をドラッグすると選択できるノード一覧が出てくるので「Primitive」を選択してください。
- Primitive:utils > Primitive
「Image chooser」の実装:

「Preview Chooser」ノードを「Save Image」ノードと差し替えします。「Save Image」は最後に使うので削除せずに残しておきましょう。このノードが実行された時に音でお知らせをして欲しいので「PlaySound 🐍」も繋げておきます。
- Preview Chooser:Image chooser > Preview Chooser
- PlaySound 🐍:utils > PlaySound 🐍
モデルを使ったアップスケール:

「Preview Chooser」のimagesアウトを「Upscale Image (using Model)」に繋ぎます。「Load Upscale Model」のUPSCALE_MODELアウトを「Upscale Image (using Model)」に繋ぎます。
- Upscale Image (using Model):image > upscaling > Upscale Image (using Model)
- Load Upscale Model:loaders > Load Upscale Model
アップスケールした画像を希望するサイズに変更:

「Upscale Image (using Model)」のIMAGEアウトを「ImageScaleToTotalPixels」に繋ぎます。
- ImageScaleToTotalPixels:image > upscaling > ImageScaleToTotalPixels
セカンドパスの実装:

サイズ調整した画像をlatent imageに変換する為に「VAE Encode」で変換します。
1回目のKSamplerを選択状態にしてCtrl + cでコピーします。そして、Ctrl + Shift + vでインプットを引き継いだままコピーできるので、繋がったまま希望する位置へ持っていきます。
位置が決まれば先ほどの「VAE Encode」で変換したLATENTを2回目のKSamplerのlatent_imageインプットに繋ぎます。
- VAE Encode:latent > VAE Encode
- KSampler:sampling > KSampler
Tiled Decodeを使ってメモリー節約:

2回目のKSamplerのLATENTアウトを「VAE Decode (Tiled)」に繋ぎます。vaeインプットには、少し遠いですが「Load Checkpoint」とつなぎます。
- VAE Decode (Tiled):_for_testing > VAE Decode (Tiled)
イメージの保存:
最後に、先ほど残しておいた「「Save Image」」に先ほどの「VAE Decode (Tiled)」のIMAGEアウトを繋ぎます。
これで実装は完了です。続いて使い方を解説しながら、パラメーターを入力します。
カスタムImg2Img Examplesの使い方
チェックポイント モデルの選択:

「Load Checkpoint」のckpt_nameでモデルを指定します。今回はDCAIでは定番のSD1.5モデルdarkSushiMixMix_225Dを使用します。モデルに関してはお好きなモデルを使用しても問題ありませんが、パラメーターをモデルに対して少し調整する必要があります。
Clip skipの設定:

A1111 WebUIでいうところのClip skip: 2にしたいので「CLIP Set Last Layer」のstop_at_clip_layerを-2に設定します。
LoRAの読み込み:

「Load LoRA」のlora_nameでLoRAモデルを選択します。今回はディテールを出したかったのでadd_detailを読み込んでいます。ウェイトを少し上げたいのでstrength_modelを1.50に設定します。
インプット画像の設定:

「Load Image」にインプット画像を読み込ませます。今回は前回の記事と同様にUnsplashからお借りした🔗ロンドンの街角の写真を読み込みます。

「Upscale Image」でSD1.5モデルに対応する大きさに変更します。widthを768heightを512に設定してcropをcenterに変更します。
「RepeatImageBatch」で後ほど使う「Preview Chooser」の低解像度サンプルの枚数を設定できます。今回は2に設定します。
ネガティブ プロンプトの入力:

ポジティブ プロンプトは自動で解析されるのでネガティブ プロンプトに下記のプロンプトをコピーしてください。ここではネガティブ エンベディングの「EasyNegative」を適応しています。※2番目のelectric cableはこのインプット画像の為のプロンプトなので他の画像を試す場合は削除してください。
(realistic:1.4), electric cable, worst quality, low quality, normal quality, lowres, text, (embedding:EasyNegative:1.2)EasyNegativeをお持ちでない方は🔗Civitaiのページよりダウンロードして\ComfyUI\models\embeddingsに置きましょう。
1stパスの設定:

生成をクリエイティブな結果にしたいのでSampling stepsを30に設定します。
モデルのスタイルを生かしたいのでCFG Scaleを3.0に変更します。
インプット画像の構図を維持したいのでDenoising strengthを0.50に設定します。
アップスケーラー モデルの選択:

Load Upscale Modelでアップスケーラー モデルを読み込みます。今回の例では4x-UltraSharp.pthを使っていますがお好きなモデルを使っても問題ありません。
再スケールの設定:

「ImageScaleToTotalPixels」のupscale_methodをlanczosに変更します。
2ndパスの設定:

ファースト パスのstepsが30なので追加で5ステップしたいのでSampling stepsを35に設定します。
プロンプトをあまり強調させない為にCFGを3.0に設定します。
サンプラーは好みで選んでも問題ありませんが、今回は1st Passと同じeuler_ancestralとbetaの組み合わせにしています。
インプット画像の構図を維持したいのでDenoising strengthを0.35に設定します。
タイルサイズの設定:

「VAE Decode (Tiled)」のtile_sizeはデフォルトの512で問題ありませんが動作が重たい時は320に下げてください。
生成:
「Queue Promt」ボタンで生成を開始してしばらくすると「Preview Chooser」に低画質の2枚の画像が出てくるので良いのが在れば選択して「Progress selected image」ボタンでアップスケール プロセスへ送ることができます。また、低画質の生成結果が気に入らないときは「Queue Promt」ボタンでもう一度低画質の生成ができるので良い結果が出るまで何度も繰り返しましょう。

以上でimg2imgの改良版が完成しました。完成後のワークフローはPatreonで無料公開していますので参考にしてください。

Inpainting

こちらもまずは、公式のInpaint Examplesから見ていきましょう。
リンク先のページにある一番上のワークフローの画像をダウンロードしてComfyUIにドラッグ アンド ドロップするか、Loadボタンより読み込んでください。
Load ImageにInpaint Examplesの上から2番目のヨセミテの写真をダウンロードして読み込ませます。
読み込みが完了したら「Load Checkpoint」ノードのckpt_nameより、お好きなモデルを読み込んでください。 ※ExampleではSD2.0インペインティング モデルの「512-inpainting-ema.safetensors」を使っていますが、通常のチェックポイント モデルでも使うことができます。
プロンプト等を変更して色々試してみましょう。
マスクについて
ComfyUIでは読み込んだ画像を右クリック メニューの中の「Open in MaskEditor」でマスクを指定できます。MaskEditorで保存した画像はClipspaceにも保持されるのでメイン メニューの「Clipspace」からでも編集できます。
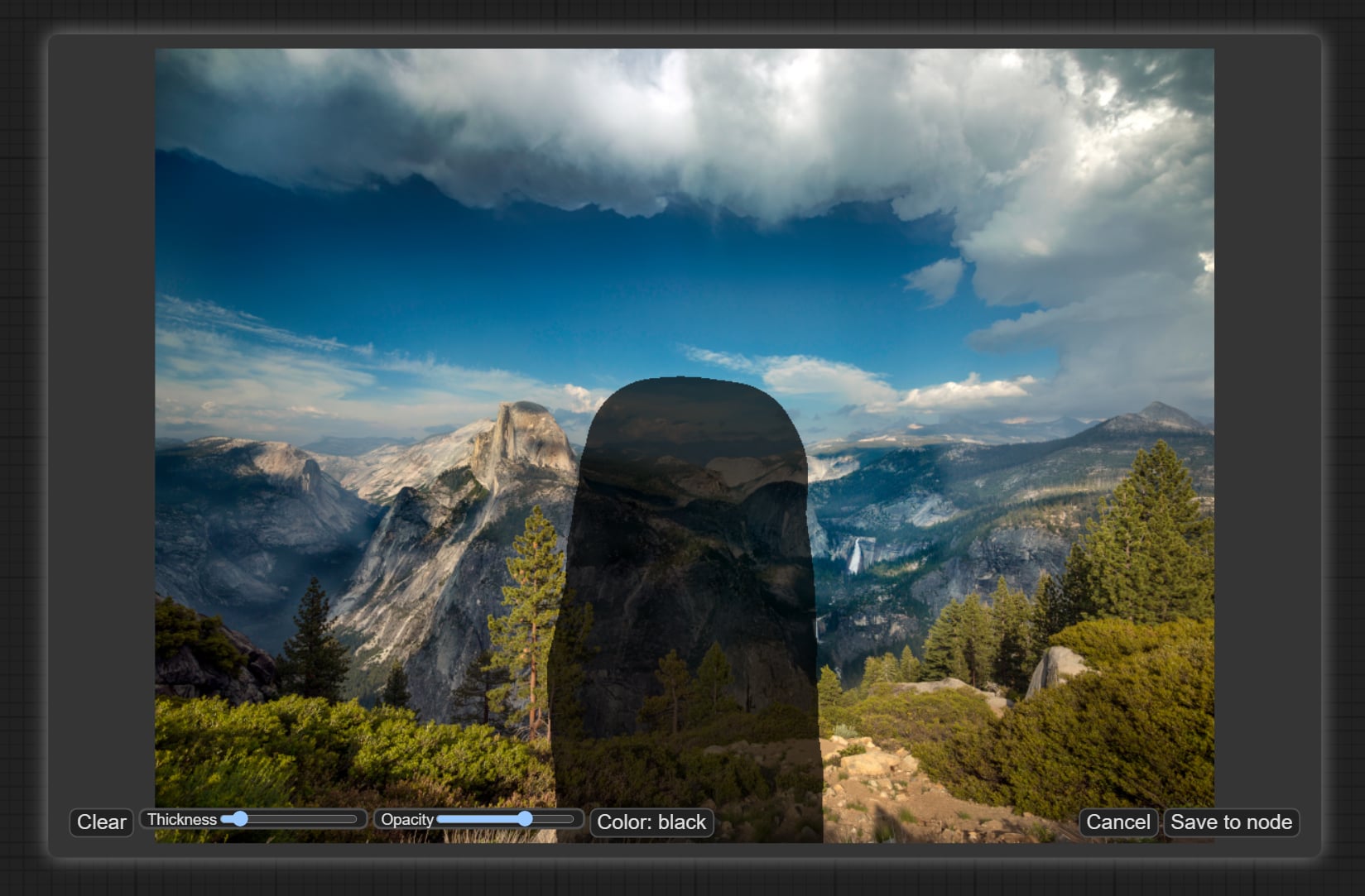
MaskEditorが使いづらい方はPhotoshopやGIMPのレイヤーマスクでマスクを作りマスク入りのPNGファイルとして保存すれば、ComfyUI内でマスクとして認識されます。
ただし、そのPNGファイルをもう一度Photoshop等で開くとマスク部分が削除されます。オリジナルの画像を上書き保存してしまわないように、初めにComfuUI用のマスク入りファイルとして別ファイルに保存することをオススメします。
公式のInpaint Examplesを改良してみる
ここからは公式のInpaint Examplesをもう少し実用的なInpaintingワークフローに改良してみようとおもいます。先ほどのimg2imgと似てはいますが、以下に組み込みたいリストを纏めました。
- Inpainting簡易モデルを使用する為の工程を実装。
- Clip skipを適応させる。
- LoRAを適応させる。
- VAEモデルを適応させる。
- ワークフローの流れを効率的にするために「Image chooser」カスタムノードを実装。
- 生成品質が良くないのでセカンドパスを実装。
- Tiledデコードを使ってメモリーの節約。
以上の項目を実装し、インプット画像に人々や露店を生成するワークフローに改良します。
カスタム ノードのインストール:
「Image chooser」を先のimg2imgで使用していたのでそのまま使います。インストールしていない方は、「🔗1-1.公式のImg2Img Examplesを改良してみる」で紹介しているのでそちらを参照してください。
Inpaintモデルのインストール:
このワークフローではチェックポイントモデルの「sd-v1-5-inpainting」と「sd-v1-5-pruned-emaonly」が必要になります。公式モデルはRunwayのHugging Faceページで公開されていたのですが、現在削除されダウンロードできない状態です。代替え案として「sd-v1-5-inpainting」はcamenduru氏がHugging Faceで公開していますのでそちらを紹介しておきます。「sd-v1-5-pruned-emaonly」についてはemmajoanne氏が公開しているページを載せておきます。
また、今回の例では説明はしませんがSDXLを使う場合は下記のモデルを使用します。
Inpaintingモデルの実装:

まずは「Load Checkpoint」を2つ呼び出してモデルをそれぞれ「sd-v1-5-inpainting」と「sd-v1-5-pruned-emaonly」に変更します。
「ModelMergeSubtract」を呼び出し、model1には「sd-v1-5-inpainting」、model2には「sd-v1-5-pruned-emaonly」を繋ぎます。
「ModelMergeAdd」を呼び出して、model1に先ほどのモデルを繋ぎ、model2に今回使いたいモデルを接続します。
この構成によりsd-v1-5-inpaintingよりsd-v1-5-pruned-emaonly部分を削除して新たに今回使いたいモデルを加えてinpaintingモデルを作っています。
- Load Checkpoint:loaders > Load Checkpoint
- ModelMergeSubtract:advanced > model_merging > ModelMergeSubtract
- ModelMergeAdd:advanced > model_merging > ModelMergeAdd
Clip skip / LoRAの適応:

メインの「Load Checkpoint」のCLIPアウトに「CLIP Set Last Layer」を繋ぎ、「CLIP Set Last Layer」のCLIPアウトに「Load LoRA」も繋ぎます。
「Load LoRA」のCLIPアウトは2つの「CLIP Text Encode (Prompt)」に繋いでください。
そして、先ほど作成した「ModelMergeAdd」のMODELアウトを「Load LoRA」のmodelインプットに繋ぎそこから「KSampler」に繋ぎます。
- CLIP Set Last Layer:conditioning > CLIP Set Last Layer
- Load LoRA:loaders > Load LoRA
インプット画像の調整:

「VAEEncodeForInpaint」ノードを削除して「Upscale Image」と「RepeatImageBatch」を追加します。
- Upscale Image:image > upscaling > Upscale Image
- RepeatImageBatch:image > batch > RepeatImageBatch
マスクの調整:

マスクのサイズもインプット画像同様に縮小する必要がある為「Convert Mask to Image」で画像に変換します。
「Upscale Image」で縮小してから境界線をぼかす為に「ImageBlur」を使いってぼかします。
そして「Convert Image to Mask」でマスクに戻します。
- Convert Mask to Image:mask > Convert Mask to Image
- ImageBlur:image > postprocessing > ImageBlur
- Convert Image to Mask:mask > Convert Image to Mask
インペイント用にデータを整える:

公式では「VAEEncodeForInpaint」を使っていましたが、今回は「InpaintModelConditioning」を使ってデータを作っていきます。
「InpaintModelConditioning」のインプットにプロンプトの2つ、縮小したインプット画像とマスクを繋ぎます。
- InpaintModelConditioning:conditioning > inpaint > InpaintModelConditioning
外部VAEの適応:

今回はVAEを別モデルにしたいので「Load VAE」を呼び出して「InpaintModelConditioning」に繋ぎます。
- Load VAE:loaders > Load VAE
Seedの共有化:

KSamplerノードの右クリック メニューよりConvert seed to inputでSeed値を外部化します。seedインプットの●をドラッグすると選択できるノード一覧が出てくるので「Primitive」を選択してください。
- Primitive:utils > Primitive
「Image chooser」の実装:

「Preview Chooser」ノードを「Save Image」ノードと差し替えします。「Save Image」は最後に使うので削除せずに残しておきましょう。このノードが実行された時に音でお知らせをして欲しいので「PlaySound 🐍」も繋げておきます。
- Preview Chooser:Image chooser > Preview Chooser
- PlaySound 🐍:utils > PlaySound 🐍
モデルを使ったアップスケール:

「Preview Chooser」のimagesアウトを「Upscale Image (using Model)」に繋ぎます。「Load Upscale Model」のUPSCALE_MODELアウトを「Upscale Image (using Model)」に繋ぎます。
- Upscale Image (using Model):image > upscaling > Upscale Image (using Model)
- Load Upscale Model:loaders > Load Upscale Model
アップスケールした画像を2ndパス用サイズに変更:

「Upscale Image (using Model)」のIMAGEアウトを「ImageScaleToTotalPixels」に繋ぎます。
- ImageScaleToTotalPixels:image > upscaling > ImageScaleToTotalPixels
2ndパス用マスクの作成:

1stパス用のマスクは縮小されているので画像に変換してアップスケールをします。
1stパス用のマスクを「Convert Mask to Image」で画像に変換します。
続いて「ImageScaleToTotalPixels」で2ndパスの画像を同じサイズにします。
そして「Convert Image to Mask」でマスクに戻します。
インペイント以外の背景をオリジナルと合成:

一度縮小してアップスケールをした元画像がぼやけているのでオリジナルと差し替えます。
「ImageCompositeMasked」を配置したらdestinationに「Load Image」を繋ぎます。sourceには2ndパスの画像を繋ぎ、maskには先ほど作成したアップスケール用マスクを繋ぎます。
- ImageCompositeMasked:image > ImageCompositeMasked
2ndパスの実装:

1stパスと同様に「InpaintModelConditioning」を使ってデータの準備をします。
positiveインプットには下記のプロンプトが入力された「CLIP Text Encode (Prompt)」を新たに作ります。clipにはLoad LoraのCLIPアウトを繋ぎます。
very detailed, masterpiece, intricate details, UHD, 8Knegativeインプットには1回目と同じCONDITIONINGアウトを繋ぎます。
vaeには「Load VAE」を繋ぎます。
pixelsには先ほど合成したImageCompositeMaskedのアウトを繋ぎます。
そしてmaskには先ほど拡大したマスクを繋いでください。
「KSampler」を配置して今作成したInpaintModelConditioningを繋いでいきます。modelと外部化させたseedには1回目と同じ接続をします。
- CLIP Text Encode (Prompt):conditioning > CLIP Text Encode (Prompt)
- KSampler:sampling > KSampler
画像鮮明化の為のアップ スケール + ダウン スケール:

最終結果を鮮明にしたいので「Upscale Image (using Model)」で拡大して「ImageScaleToTotalPixels」で任意の大きさに縮小します。これにより最終結果を鮮明に出すことができます。
イメージの保存:
最後に残しておいた「「Save Image」」に先ほどの「ImageScaleToTotalPixels」のIMAGEアウトを繋ぎます。
これで実装は完了です。続いて使い方を解説しながら、パラメーターを入力します。
カスタムInpaint Examplesの使い方
インプット画像の読み込みとマスクの作成:

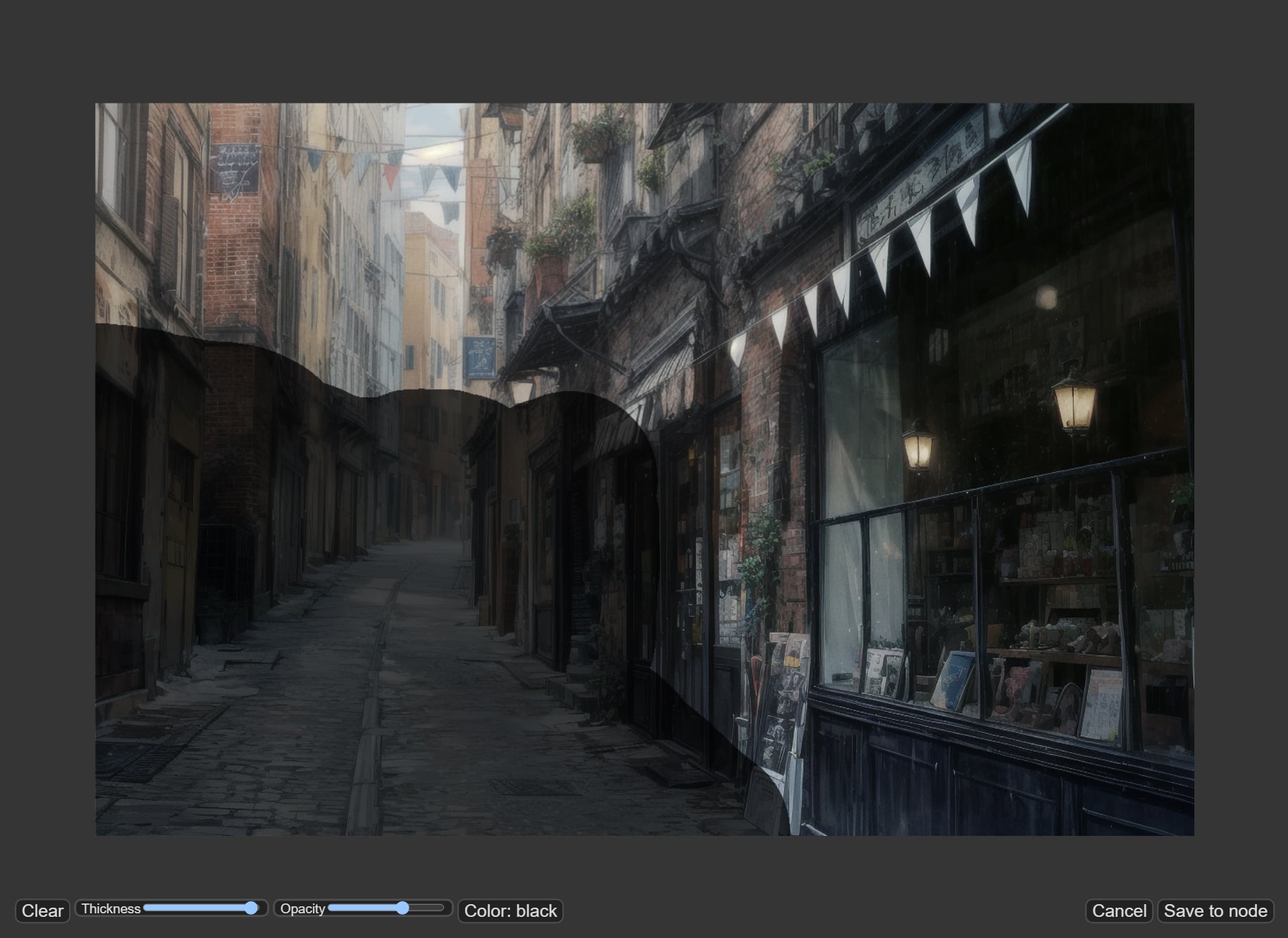
このワークフローではインプット画像の大きさが限定されています。正しい大きさのインプット画像はGoogle Driveに置いていますので、そちらをお使いください。
上記の画像を「Load Image」にドラッグ アンド ドロップするか「choose file to input」ボタンで読み込みます。
読み込みが完了したらノードの右クリック メニューから「Open in MaksEditor」でマスク エディターを開きインペイントしたい部分を塗りつぶしてください。今回は道を歩く人々と露店を描きたいので任意の範囲をマスクしてください。
チェックポイント モデルの選択:
「Load Checkpoint」のckpt_nameでモデルを指定します。今回もdarkSushiMixMix_225Dを使用します。モデルに関してはお好きなモデルを使用しても問題ありませんが、パラメーターをモデルに対して少し調整する必要があります。
Clip skip / LoRAの設定:

今回もClip skip: 2にしたいので「CLIP Set Last Layer」のstop_at_clip_layerを-2に設定します。
LoRAに関しては今回は使わないのでバイパスしておきます。LoRAを使いたい場合はバイパスを解除してお使いください。
インプット画像を調整:

インプット画像をSD1.5モデルに適した大きさに縮小します。画像・マスクそれぞれに繋いだ「Upscale Image」のwidthを768heightを512に設定します。
マスクの境界線をぼかしたいので「ImageBlur」のblur_radiusを10にします。
VAEの選択:

VAEは定番のvae-ft-mse-840000-ema-pruned.safetensorsを選択します。
プロンプトの入力:
プロンプトは道を歩く人々と露店をインペイントしたいので下記の様に記述してください。
ポジティブ プロンプトmasterpiece, peoples, adventurer, ultra detailed, medival, fantasy, marketworst quality, low quality, normal quality, lowres, text, ugly, ugly face, deformed, deformed face, bad anatomy1stパスの設定:

少しだけ書き込み量を増やしたかったのでstespは25に設定します。
cfg/sampler_name/schedulerはデフォルトのままでもよかったのですがschedulerをbetaに変更します。
denoiseはインプット画像に馴染ましたかったので0.90にします。
アップスケールの設定:

アップスケールモデルを4x-UltraSharpにします。
マスクのアップスケール メソッドをスムーズにしたいのでlanczosに変更します。
2ndパスの設定:

stepsは1stパスが25だったのでプラス10をして35にします。
sampler_nameは少し重たいですがdpmpp_sdeを使い、schedulerはkarrasに設定します。
画像鮮明化の設定:

最後の画像鮮明化の設定はモデルに4x-UltraSharpを使います。
「ImageScaleToTotalPixels」のmagapixelsを1.50にして少し大きくしています。
生成:
今回も生成方法はimg2imgの時と同じで「Queue Promt」ボタンで生成を開始してしばらくすると「Preview Chooser」に低画質の2枚の画像が出てくるので良いのが在れば選択して「Progress selected image」ボタンでアップスケール プロセスへ送ることができます。また、低画質の生成結果が気に入らないときは「Queue Promt」ボタンでもう一度低画質の生成ができるので良い結果が出るまで何度も繰り返しましょう。

以上でInpainting Exampleの改良版が完成しました。完成後のワークフローはPatreonで無料公開していますので参考にしてください。

まとめ
今回はComfyUIでimage2imageの使用方法を紹介させていただきました。基本編と言うことであまり複雑にならないようにワークフローをカスタムいしましたが、カスタム ノードの「ComfyUI-Inpaint-CropAndStitch」を導入すればA1111 WebUIでいうところのOnly maskedモードの様なインペイント部分をスケール アップしてからインペイントして元画像に合成する方法などもあります。また、機会が在れば複雑なインペイント ワークフローを紹介したいと思います。
最後までお読みいただきありがとうございます。
もし少しでも参考になったら、ぜひ「いいね」で応援してください!