A1111 WebUI SD1.5 / SDXL コントロールネットの詳しい使い方

ControlNetを導入することによりさまざまな機能が追加されます。画像のディテールを追加したりラフ絵から画像を生成するimg2imgの拡張機能など便利な機能を使うことができるでしょう。今回はWebUIにさまざまな機能を追加してくれるControlNetの使い方を詳しく解説します。解説はコントロールネットバージョンが執筆時のv1.1.455の説明です。










ControlNetのインストール
ControlNetのインストールは「Extensions」タブより行います。順を追って説明します。
- 「Extensions」タブをクリックしてページに行きます。
- 「Install from URL」タブよりURL入力ページに行きましょう。
-
下記のリポジトリURLを貼り付けます。
https://github.com/Mikubill/sd-webui-controlnet - 「Install」ボタンよりインストールしましょう。
- インストールが完了したら、「Installed」タブに行き一覧に「sd-webui-controlnet」があるのを確認します。
- 確認できたら「Apply and restart UI」より再起動します。
- 再起動後パラメーターーエリアにControlNetが表示されればインストール完了です。
ここでは簡単に方法を説明しましたが、下記の記事にて詳しく説明しているので解らなかった方は参考にしてください。

ControlNetのモデルのダウンロード
インストールが完了したらモデルをダウンロードしてstable-diffusion-webui\extensions\sd-webui-controlnet\modelsに置きましょう。コントロールネットのモデルは公式のモデル以外にもさまざまです。一度にすべてのモデルをダウンロードするとかなりの容量があるので、まずは自分の試したいモデルのみをダウンロードしてみましょう。希望するpth又はsafetensorsファイル、あとは同じファイル名のyamlファイルがある場合は一緒にダウンロードしましょう。
Stable diffusion 1.5
標準のコントロールネット1.1モデル標準のモデルはそれぞれLARGE / MEDIUM / SMALLの3種類あります。ご自身のVRAMに合わせてダウンロードしましょう。
- 🔗LARGE:コントロールネットの作者が公開しているモデルです。それぞれのモデルは1.45GBとなっています。使いたいモデルのyamlファイルも同じ場所にダウンロードしましょう。
- 🔗MEDIUM:ComfyUIの作者が公開しているモデルです。LARGEの半分のサイズでモデルサイズが723MBとなっています。ファイル名が「control_v11e_sd15_xxxx」のファイルをダウンロードしましょう。
- 🔗SMALL:コチラもComfyUIの作者が公開しているモデルです。各モデルは136MBとかなり軽量になっています。ファイル名が「control_lora_rank128_v11e_sd15_xxxx」のファイルをダウンロードしましょう。
🔗sd_control_collection:公式から紹介されているモデルです。基本的にはSDXL用のモデルが置いていますがrecolor/ip-adapterのSD1.5モデルがダウンロードできます。
ControlNet++ControlNet++は標準モデルよりも精度の高いモデルとなっています。
- 🔗LARGE (fp32):canny/depth/hed/lineart/segのモデルがあります。それぞれのモデル(1.45GB)をダウンロードして名前をdiffusion_pytorch_modelから変更しましょう。例:controlnet++_canny_sd15_fp32
- 🔗MEDIUM (fp16):canny/depth/hed/lineart/segのモデルがあります。
Stable diffusion XL
SDXLでコントロールネットを使いたい場合は下記のモデルをダウンロードしましょう。
- 🔗sd_control_collection:公式から紹介されているモデルです。
- 🔗qinglong_controlnet-lllite:qinglongshengzhe氏が公開しているモデルです。
- 🔗TTPLanet_SDXL_Controlnet_Tile_Realistic:ttplanet氏が公開しているTile用のモデルになります。
- 🔗iroiro-lora:2vXpSwA7氏が公開しているコントロールネット用テストモデルです。
- 🔗MistoLine:TheMistoAI氏が公開しているモデルでCanny/Lineart/SoftEdge等の線系のディテクトマップに向いているモデル「mistoLine_fp16.safetensors」がダウンロードできます。
- 🔗kataragi’s HF page:kataragi氏が公開しているモデルでInpaint/Recolor/Lineart/Line2color用モデルがダウンロードできます。
- 🔗xinsir’s HF page:xinsir氏が公開しているモデルでCanny/Openpose/Scribble/Scribble-Anime用モデルがダウンロードできます。
IP-Adapter anime
IP-Adapterのインプットは基本的に実写の画像が向いておりイラストではあまり良い結果が得られません。下記のモデルを使用すれば比較的にインプットと近いイラストが生成されます。
- 🔗IP-Adapter anime fine tune:arnon氏が公開しているモデル。Contrl TypeはIP-Adapterでip-adapter_clip_hと併用しましょう。
- 🔗IP-Adapter-plus anime fine tune:Contrl TypeはIP-Adapterでip-adapter_clip_hと併用します。
T2I-Adapter Models
T2I-Adapterは標準のコントロールネットより軽量に動作するように作られています。モデルは下記よりダウンロードしましょう。
- 🔗T2I-Adapter/models:公式のTencentARCが公開しているSD1.5モデルです。
- 🔗ControlNet T2I-Adapter Models:TencentARC公式のモデルがpthなのでsafetensor版を紹介します。ダウンロードはControlnetとConfigの両方ともダウンロードしてください。
- 🔗T2I-Adapter/models_XL:公式のTencentARCが公開しているSDXLモデルです。Canny/Open pose/sketchモデルがあります。
ControlNetでできること
まずはControlNetでできる一覧を見ていきましょう。
- 構図の参照:インプット画像を参考に、生成画像の構図をコントロールします。
- 人物の参照:インプット画像の人物を参考に、新しい構図に同じ人物のイラストを生成します。
- ポーズの参照:インプット画像やOpen poseを参照に、生成画像のポーズをコントロールします。
- インペイント:インプット画像に、マスク範囲を指定してインペイントします。
- カラースキームの変更:インプット画像のカラースキームを変更します。
- 生成画像の細密化:インプット画像を細密化して、ディテールのある画像を生成します。
ControlNetの使い方
インターフェイスの説明
デフォルトUI
- ユニットタブ:複数のコントロールネットを適応する時に使用。通常はUnit 0のみの設定で使用します。
- インプットタブ:インプット画像をシングル、バッチ、マルチの切り替えをするタブ。また下部にあるアイコンボタンでキャンバスを作成したりWEBカメラを使ったりします。
- Enable:コントロールネットを有効化するチェック ボックス
- Low VRAM:VRAMが8GBより少ない場合はこのチェック ボックスをオンにします。
- Pixel Perfect:アノテーターの解像度を自動で調整します。
- Allow Preview:Preprocessorプレビューを表示します。プレビューはPreprocessorの横にある💥ボタンで表示します。
- Effective Region Mask:オンにすることでコントロールネットの適応範囲のマスクを読み込む事ができます。
- Control Type:コントロールタイプを選択します。選択するとそれに合ったPreprocessorとModelが自動で読み込まれます。
- Preprocessor(アノテーター):コントロールネットを適応する前に指定したアノテーターでディテクト マップを作成します。💥ボタンでプレビューを見ることができます。
- Model:コントロールネット モデルを選択します。🔄ボタンでリストを更新できます。
- Control Weight:コントロールネットのウェイトを調節します。値が低いほどプロンプトが優先されます。
- Starting Control Step:コントロールネットをどのステップで開始するかを指定します。0.0-1.0の間で指定します。例:Stepsが20の場合0.5は10ステップ目から適応します。
- Ending Control Step:コントロールネットをどのステップで開始するかを指定します。0.0-1.0の間で指定します。
- Control Mode:コントロールネットとプロンプトとのバランスを指定します。
- Resize Mode:インプット画像と生成イラストの大きさが違う場合の拡大/縮小方法を指定します。
- Batch Options:バッチモードを使用時にバッチの適応方法を指定します。
インプットモードについて
インプットモードはインプットタブより変更できます。
Single Image
1枚の画像をコントロールネットに入力します。画像を読み込んだ後はキャンバスとしてマスクを指定します。読み込み後Control Weightの下にResolutionの項目が出てきますので指定しましょう。
Batch
フォルダーを指定してフォルダー内の画像をコントロールネットに入力できます。Batch countとBatch sizeは1のままで指定したフォルダー内の画像をすべて生成します。(※WebUIのv1.10.1で検証したところ生成画像の保存はされますが。プレビューは表示されませんでした。)
Multi-Inputs
複数のインプット画像を入力して混ぜる事ができます。「Upload Images」ボタンより画像を選択します。各インプット画像のウェイトの指定はできません。
Control Typeについて
Control Typeを指定できます。指定したタイプによって自動でPreprocessorとModelを選択します。また、タイプにより入力できるパラメーターが変化します。
始めて使うプリプロセッサの場合、必要なデータをダウンロードする為、時間が掛かる場合があります。とくにIP-AdapterやRevision等で使うclipvisionはclip_h/clip_g/clip_vitlの3つ合わせると7.38GBもあるのでストレージが少ない場合は要注意です。ダウロードしたファイルは\stable-diffusion-webui\extensions\sd-webui-controlnet\annotator\downloadsに格納されています。
All:
デフォルトのタイプ。インストールされているすべてのPreprocessorとModelを選択できるので自身で組み合わせて使用します。
Canny:

- canny:PythonライブラリのOpenCVの機能、Cannyを使ったedge-ditectionになります。
- invert (from white bg & black line):スケッチ等白バックに黒線のインプット画像の時にコチラを使用します。
シンプルでシャープなラインを濃淡の大きい部分を元に作成します。パラメーターにLow ThresholdとHigh Thresholdが現れるので、適応範囲のしきい値を調節できます。また、白バックに黒線の様な画像は「invert」を選択しましょう。
Depth:

- depth_midas:MiDaS学習データセットを使った深度検出。v2.1が使われていて、人物の書き換えなどに向いています。
- depth_zoe:ZoeDepth学習データセットを使った深度検出。エッジがソフトな感じになりますが、中距離程度の奥行きを検出します。
- depth_leres++:LeReS + pix2pix学習データセットを使った深度検出。下記のノーマル版よりさらに細かいところまで検出してくれます。クッキリとしたディテクトマップを生成します。
- depth_leres:LeReS + pix2pix学習データセットを使った深度検出。検出は深いところまでできます。エッジは少しぼやけた感じいなります。インプット画像の背景も参考にしたい場合はコチラをオススメします。
- depth_hand_refiner:MeshGraphormer + HRNetsを使って手を修正します。img2imgのInpaintingで手の範囲を指定して使用します。
- depth_anything_v2:DINOv2学習データセットを使った深度検出。クッキリと人物を検出させる時に使えます。奥行きはMiDaSに近い感じです。
- depth_anything:DepthAnythingV2学習データセットを使った深度検出。コチラも人物検出したい時にオススメです。

インプット画像を解析して、デプス マップを作成します。人物などを置き換えるときに使います。
IP-Adapter:

- ip-adapter-auto:選択したコントロールネット モデルに適したPreprocessorを自動的に選択します。
- ip-adapter_clip_h:CLIP ViT-H/14 – LAION-2Bを使って人物を摘出します。
- ip-adapter_pulid:insightface embeddingとCLIP embeddingを使って人物を摘出します。
- ip-adapter_face_id_plus:LoRAを併用する必要があります。標準版のface IDと、さらにCLIPを使って顔のみをクローンする時に使います。
- ip-adapter_face_id:LoRAを併用する必要があります。face IDを使って顔のみをクローンする時に使います。
- ip-adapter_clip_sdxl_plus_vith:SDXLのみ使用可能。CLIP ViT-H/14 – LAION-2Bを使って人物を摘出します。
- ip-adapter_clip_g:SDXLのみ使用可能。CLIP ViT-bigG/14 – LAION-2Bを使って人物を摘出します。
IP-adapter (Image Prompt adapter)はインプット画像の人物を特定して、新しい構図で生成できます。パラメーターにWeight Typeが現れるのでウェイトタイプを選択できます。また、Control Modeは指定できません。IP-Adapterの一部のプリプロセッサにはLoRAを一緒に使う必要があります。インプット画像は写真を推奨しておりイラストでは上手くいかないことが多いでしょう。
Inpaint:

- inpaint_only:インペイントのみの場合コチラを使用します。
- inpaint_only+lama:LaMaを使ってインペイントします。inpaint_onlyよりクリアーな生成ができます。
- inpaint_global_harmonious:A1111のインペイント パスを使ってインペイントします。A1111のimg2imgでコントロールネットをオンにして使います。
インプット画像に指定したマスク範囲をプロンプトで書き換えることができます。
Instant-ID:

- instant_id_face_keypoints:instantIDのモデル「control_instant_id_sdxl」と併用します。
- instant_id_face_embedding:ip-adapterのモデル「ip-adapter_instant_id_sdxl」と併用します。
SDXLのみですが、インプット画像の顔を摘出して、その顔を参照にイラストを生成します。使用するにはipadapter modelとinstantID modelをダウンロードして、UNITを2つ使いそれぞれのモデルを設定する必要があります。
InstructP2P:

Instruct Pix2Pixはインプット画像をプロンプトにしたがって書き換えることができます。例:夏の風景を冬の風景に変更
Lineart:

- lineart_standard:Lineart標準のプリプロセッサになります。
- invert (from white bg & black line):Lineart標準のプリプロセッサですが反転された背景が白、ラインが黒の画像の時に使います。
- lineart_realistic:写真やリアルなCG等からディテクトマップを生成します。細かな線まで摘出できます。
- lineart_coarse:線の強いディテクトマップを生成します。
- lineart_anime_denoise:アニメ調のイラストからディテクトマップを生成します。デノイズ版なので細かな線は摘出されません。
- lineart_anime:アニメ調のイラストからディテクトマップを生成します。

インプット画像のアウトラインでディテクト マップを作成します。線画に色を付ける等イラスト系に適しています。
MLSD:

- mlsd:MLSD標準のプリプロセッサになります。
- invert (from white bg & black line):インプット画像が白バック+黒ラインの場合はコチラを使いましょう。
Mobile Line Segment Detectionはインプット画像の直線部分を検出してディテクト マップを作成します。パースを維持するので、建物や人口物などに向いています。
NormalMap:

- normal_bae:Bae法線マップを生成します。背景を含めたい時に使います。
- normal_midas:MiDaSを使って法線マップ。人物のみを参照したい時に使います。
- normal_dsine:SD1.5のモデルがない為、SDXLのみ使用可能。Baeより高品質な法線マップを生成します。コントロールネット モデル「bdsqlsz_controlllite_xl_normal_dsine」が必要になります。

インプット画像の法線マップを作成します。Depthに近いですが質感等ディテールのあるディテクトマップを作成します。
OpenPose:

- openpose_full:全身のOpenPoseを生成します。
- openpose_hand:標準のopenposeに加え手や指も摘出します。
- openpose_faceonly:顔のみを摘出します。表情なども摘出します。
- openpose_face:標準のopenposeに加え 顔 + 表情を摘出します。
- openpose:標準のプリプロセッサ。目・鼻・耳・首・肩・肘・腰・膝・足首を摘出します。
- dw_openpose_full:openpose_fullの強化版になります。
- densepose_parula (black bg & blue torso):DensePoseを使って人物のポーズを摘出します。専用のモデル「🔗Controlnet for DensePose」が必要になります。
- densepose (pruple bg & purple torso):DensePoseを使って人物のポーズを摘出します。専用のモデル「🔗Controlnet for DensePose」が必要になります。
- animal_openpose:動物から摘出する時に使います。専用のモデル「🔗animal_openpose」が必要になります。
インプット画像の人物よりOpenPoseスケルトンを作成します。人物のポーズを使いたい時に使用します。
Recolor:

- recolor_luminance:インプット画像の明るさに基づいて色を付けます。
- recolor_intensity:インプット画像の色の強度に基づいて色を付けます。

インプット画像の色を変更したり、モノクロの写真に色付けする事ができます。プリプロセッサは輝度または色強度の2つより選択できます。
Reference:

- reference_only:インプット画像をアテンション レイヤーとして読み込みます。
- reference_adain+attn:アテンションとAdaIN (Adaptive Instance Normalization)を使ってスタイルを転送します。
- reference_adain:AdaINを使ってスタイルを転送します。
インプット画像をリファレンスとして使います。コントロールネットModelは使いません。パラメーターにStyle Fidelityが現れるのでControl ModeがBalancedの時のみスタイルの忠実性を設定できます。
Revision:

- revision_clipvision:標準のプリプロセッサです。プロンプトも影響されます。
- revision_ignore_prompt:プロンプトが無視されてCLIPで解析されたプロンプトのみを使います。
SDXLのみですが、インプット画像をCLIPを使いプロンプトを解析して、生成されたプロンプトを元に生成します。インプット画像は使わないので、まったく違うイラストが生成される場合があります。
Scribble:

- scribble_pidinet:Pixel Difference network (Pidinet)を使って輪郭を摘出します。この中では一番シンプルなディテクトマップを生成します。
- invert (from white bg & black line):白背景 & 黒線のインプット画像の時に使います。
- scribble_xdog:EXtended Difference of Gaussian (XDoG)を使って輪郭を摘出します。ディテールのあるディテクトマップを生成します。
- scribble_hed:Holistically-Nested Edge Detection (HED)を使って輪郭を摘出します。色やスタイルを変更する時に使います。

スケッチやラインアートを入力時に使用します。綺麗な線のディテクト マップを作成します。
Segmentation:
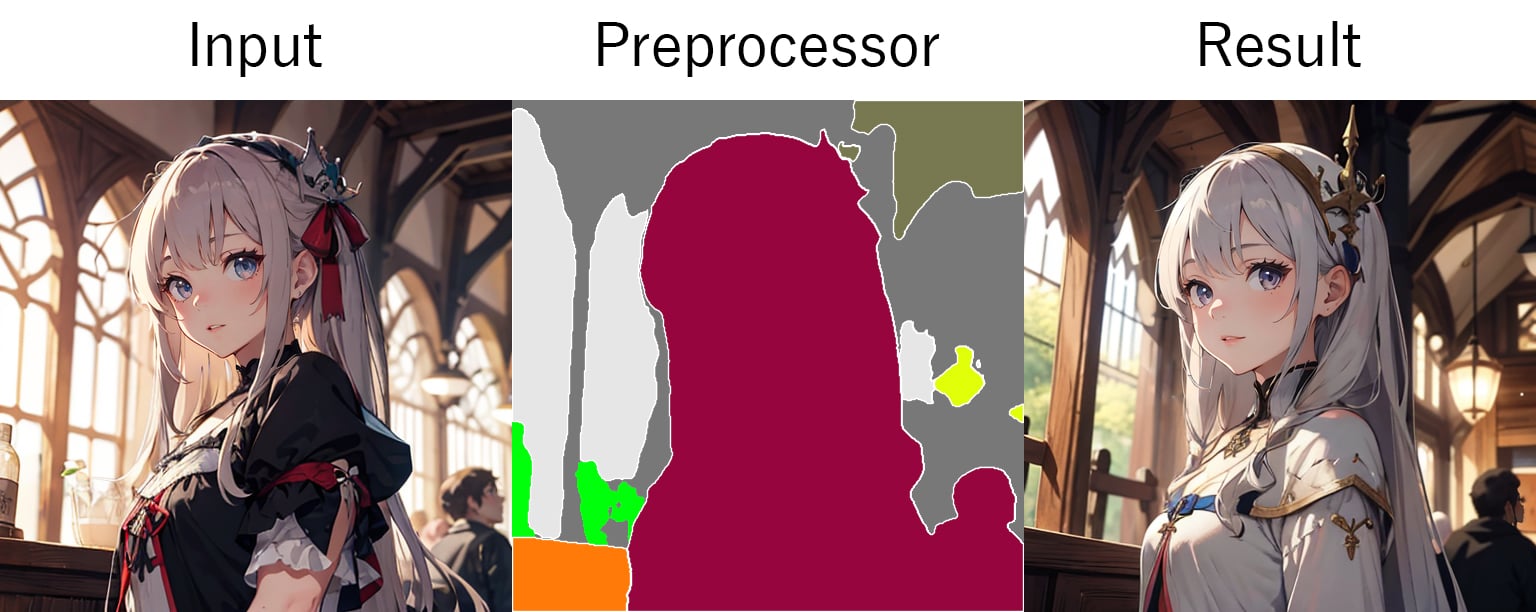
- seg_ofade20k:ADE20Kデータセットで学習されたUniFormer (uf)をつかって分割します。
- seg_ufade20k:ADE20Kデータセットで学習されたOneFormer (of)をつかって分割します。
- seg_ofcoco:COCOデータセットで学習されたOneFormer (of)をつかって分割します。
- seg_anime_face:SDXLのみですがアニメ調のインプット画像の時に使います。専用のモデル「🔗bdsqlsz_controlllite_xl_segment_animeface.safetensors」が必要になります。
- mobile_sam:MobileSAMをつかって分割します。※Controlnet v1.1.455で追加されましたが筆者の環境ではエラーで使えませんでした。

インプット画像の色や濃淡に基づいて分割されたディテクト マップを作成します。
Shuffle:

- shuffle
インプット画像をごちゃ混ぜにしてそこからカラースキームやスタイルを転送します。元の構図を維持したい場合はPreprocessorをnoneにしてみましょう。
SoftEdge:

- softedge_pidinet:Pixel Difference Convolution(table5_pidinet)を使って輪郭を摘出します。
- softedge_teed:Tiny and Efficient Edge Detector (TEED)を使って輪郭を摘出します。ディテールのあるディテクトマップを生成します。
- softedge_pidisafe:pidinetのセーフタイプで標準では消えてしまう個所をあらかじめ量子化して保護します。ディテクトマップはpidinetよりグラデーションの少ないマップになります。
- softedge_hedsafe:HEDのセーフタイプです。ディテクトマップはHEDよりグラデーションの少ないマップになります。
- softedge_hed:Holistically-Nested Edge Detectionを使って輪郭を摘出します。
- softedge_anyline:Anylineを使って輪郭を摘出します。

スムーズなラインをインプット画像のオブジェクトの周りに作成します。
SparseCtrl:
Preprocessor- scribble_pidinet:pidinetを使ってディテクトマップを生成します。
- scribble_xdog:XDoGを使ってディテクトマップを生成します。
- scribble_hed:HEDを使ってディテクトマップを生成します。
AnimateDiffを使ってtext2videoを生成するときに使います。スムーズなアニメーションを生成できます。
T2I-Adapter:

- t2ia_style_clipvision:CLIP visionを使ってembeddingを生成します。
- t2ia_sketch_pidi:pidinetを使ってディテクトマップを生成します。
- t2ia_color_grid:インプット画像のカラーパレットを生成します。
T2I-AdapterはControlNetよりも軽量で高速な生成ができます。TencentARC/T2I-Adapterからモデルをダウンロードします。style/sketch/colorがつかえます。
Tile:

- tile_resample:標準のプリプロセッサ。インプット画像をタイルサンプリングします。
- tile_colorfix+sharp:色味とシャープを維持したままタイルサンプリングします。
- tile_colorfix:色味を維持したままタイルサンプリングします。
- blur_gaussian:ブラーの掛かったタイルサンプリングをします。
インプット画像をタイル状に分割して、タイルごとに処理することにより細密化します。SD ultimate upscaleを併用してアップスケールにも使われます。
ControlNetの使用例
構図の参照
ControlNetで構図を参照する方法はいくつかありますが、ここではその中の1つ、Depthを使って人物を書き換えてみましょう。
-
インプット画像を読み込みましょう。
上記のインプット画像をダウンロード、または生成してインプットに読み込みます。

Prompt: 1girl, medieval Negative prompt: EasyNegative Steps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 7, Seed: 3801941407, Size: 768x512, Model: darkSushiMixMix_225D, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Clip skip: 2, Version: v1.10.1 - パラメーターの「Enable」をオンにしてコントロールネットを有効化します。
- パラメーターの「Pixel Perfect」をオンにして、インプット画像を生成画像の大きさに自動で調節しましょう。
- 今回はDepthを使ってディテクトマップを作りたいので「Control Type」は
Depthを選択します。 - 「Preprocessor」を
depth_anything_v2に変更して、「Model」はcontrol_v11f1p_sd15_depthを選択します。 - 「Control Weight」は少しウェイトを落とした
0.85に設定しましょう。これでコントロールネットの設定は終わりです。次は生成パラメーターを設定します。 -
ポジティブ プロンプトに下記のプロンプトを入力してください。
knight, ultra detailed, masterpiece -
続いて、ネガティブ プロンプトに下記のプロンプトを入力してください。
worst quality, low quality, normal quality, lowres - 生成サイズを
Width: 768, Height:512に設定しましょう。 - 他のパラメーターはデフォルトのままで問題ありません。「Generate」ボタンで生成しましょう。
以上で人物が騎士に変わったイラストを生成できたと思います。気に入ったイラストが生成できたらSeedをコピーしてHires. fixを使ってアップスケールしてみると良いでしょう。
構図の参照例の最終結果
人物の参照
人物を参照する場合はIP-AdapterやInstant-IDを使います。今回はIP-Adapterを使い苦手とするイラスト系のインプット画像をつかって生成する方法を解説します。コントロールネットモデルは「ipAdapterAnimeFine_v10」を使うのでダウンロードしておきましょう。また、手順にADetailerを使っています。無くても問題ないですがインストールすることをオススメです。
- インプット画像を読み込みましょう。

Prompt: 1girl, solo, cute face, (simple background:1.1), upper body, medieval, hyper detailed, masterpiece Negative prompt: nsfw, worst quality, low quality, normal quality, lowres Steps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 4, Seed: 580272187, Size: 512x512, Model: darkSushiMixMix_225D, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Clip skip: 2, ADetailer model: face_yolov8n.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer version: 24.9.0, Version: v1.10.1 - パラメーターの「Enable」と「Pixel Perfect」を有効化します。
- イラスト系のインプット画像を使って人物を参照したいので「Control Type」は
IP-Adapterを選択して「Preprocessor」にip-adapter_clip_hそして「Model」にipAdapterAnimeFine_v10を選択しましょう。 - コントロールネットの影響力が強いので「Control Weight」を
0.6にします。 - 少しだけ要素を書き込んでほしいので「Ending Control Step」を
0.9にしましょう。 -
コントロールネットの設定ができたので、次はポジティブ プロンプトに下記を入力してください。
medieval, outdoor, sky, mountain, hyper detailed, masterpiece -
そして、ネガティブプロンプトに下記を入力してください。
nsfw, worst quality, low quality, normal quality, lowres - 生成サイズを
Width: 768, Height:512に設定します。 - コントラストが高い画像が生成されるので「CFG Scale」を
4に設定しましょう。 - ADetailerがインストールされている場合はオンにしてください。
以上で入力した人物が山に居るイラストを生成できたと思います。コントロールネットのモデルの癖が強く出てしまうので完全にキャラクターを参照することは難しいですが、ADetailerを使うことで少しチェックポイントモデルに近づくのでをオススメです。
人物の参照例の最終結果
ポーズの参照
Openposeを使えばインプット画像から人物のポーズを解析して参照できます。
- インプット画像はUnsplashからお借りした🔗昼間緑の植物とストリングライトのそばに立つ2人の女性になります。この写真をキャンバスにドラッグもしくはクリックして読み込みましょう。サイズは中間もしくはSをダウンロードします。

- パラメーターの「Enable」と「Pixel Perfect」を有効化しましょう。
- 今回はOpenPoseを使うので「Control Type」は
OpenPoseを選択します。 - 「Preprocessor」は複数人の解析をしたいので高機能版の
dw_openpose_fullを選択します。 - 「Model」はSD1.5で生成するので
control_v11p_sd15_openposeを選択しましょう。 - 生成画像を横長にしたいので「Resize Mode」を
Resize and Fillにします。 - ここまで来たらインプット画像からスケルトンを作っていきましょう。Preprocessorの隣にある💥ボタンを押して解析をしましょう。
- 解析結果がでたらPreprocessor Previewエリアにあるeditボタンを押してエディターを開きましょう。

- 生成したいのは後ろ姿なので顔の部分が邪魔をすることがあるので消します。
- まずはポーズコントロールにあるPerson 1から編集していきましょう。Person 1の横にある>をクリックするとポイント一覧が表示されます。
- まずはFaceの左にあるxボタンで表情ポイントを削除します。つづいてnoseの横にある目のボタンで非表示にしましょう。そして、下の方にあるright_eye/left_eye/right_ear/left_earを非表示にします。

- Person 2も同じように顔の部分を非表示にします。
- スケルトンの修正が完了したら上にある「ControlNetにポーズを送信」で確定しましょう。

- 今回の例ではコントロールネットを複数使ってみましょう。ユニットタブの「ControlNet Unit 1」をクリックして2番目のコントロールネットを設定します。
- インプット画像はUnit 0と同じ画像を読み込みます。
- パラメーターの「Enable」と「Pixel Perfect」を有効化しましょう。
- 「Control Type」は
Depthを選択し、「Preprocessor」はdepth_anything_v2を使います。「Model」はcontrol_v11f1p_sd15_depthを選択しましょう。コントロールネットの設定は以上です。 -
次はポジティブ プロンプトに下記を入力してください。
art, correct perspective, olive tree plantation, medieval, hyper detailed, masterpiece -
そして、ネガティブプロンプトに下記を入力してください。
face, worst quality, low quality, normal quality, lowres - 生成サイズを
Width: 768, Height:512に設定します。 - 「Sampling steps」を
30に設定しましょう。残りのパラメーターーはデフォルトのままで問題ありません。 -
「Generate」ボタンを押して生成を開始します。気に入った構図が生成できたらHires.fixに下記の値を入力してプレビューエリアの✨ボタンでアップスケールしましょう。
Hires. fix: off Upscaler: R-ESRGAN 4x+ Hires steps: 15 Denoising strength: 0.35 Upscale by: 2
以上でポーズの参照したイラストが生成されたと思います。
ポーズの参照例の最終結果
生成画像の細密化
コントロールネットで生成画像を細密化するにはTileを使用しましょう。また、後半ではSD ultimate upscaleを使ってアップスケールも解説します。
-
インプット画像を読み込みましょう。
上記のインプット画像をダウンロード、または生成してインプットに読み込みます。

Prompt: floating island, ultra detailed, masterpiece Negative prompt: worst quality, low quality, normal quality, lowres, text Steps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 7, Seed: 865422851, Size: 768x512, Model: darkSushiMixMix_225D, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Clip skip: 2, Version: v1.10.1 - パラメーターの「Enable」と「Pixel Perfect」を有効化しましょう。
- 「Control Type」は
Tileを選択しましょう。 - 「Preprocessor」は
noneもしくはtile_resampleを選択します。 - 「Model」はSD1.5で生成するので
control_v11f1e_sd15_tileを選択しましょう。 - 「Control Weight」は
1のまま使います。この値はインプット画像の強度なので下げると違った画になってきます。0.5-1.0辺りで設定しましょう。 - 「Ending Control Step」も
0.7に設定しましょう。この値はどの段階でコントロールネットの適応を終了する値なので下げるとそこから新しい要素が書き込まれます。これも0.5-1.0辺りで設定しましょう。 - 後の設定はデフォルトのままで「Generate」ボタンを押して生成を開始します。
- 満足のいく結果が出てきたらプレビューエリアの🖼️ボタンでimg2imgに送りましょう。
-
img2imgに切り替わったらポジティブ プロンプトを下記の様に書き換えましょう。ネガティブ プロンプトはそのまま使います。
hyper detailed - 「Sampling steps」は
30に設定しましょう。 - 「Denoising strength」はどれだけインプット画像に近づけるかの値(0だとインプット画像になります。)なので
0.4にしましょう。 - 「Resize to」から「Resize by」に変更して「Scale」を
2に設定します。 - 「Script」から
Ultimate SD upscaleを選択しましょう。一覧にない場合は🔗Ultimate SD upscaleをインストールしてください。 - 「Upscaler」は好みで選択してください。例では
R-ESRGAN 4x+を使っています。 - 設定は以上です。「Generate」ボタンを押して生成を開始しましょう。
Tileサンプリングを使って既存の画像に書き込みできる事ができました。SDXLモデルを使えばさらに高細密なイラストも生成できます。
生成画像の細密化例の最終結果
まとめ
今回A1111 WebUIにさまざまな機能を追加してくれるコントロールネットを紹介させてもらいました。以前はSD1.5用のモデルしかありませんでしたがSDXLのモデルもどんどん出てきています。話題のFlux.1のコントロールネットも登場(ComfyUIで使用可能)していて、画像生成には欠かせないエクステンションとなってきました。次はComfyUIでのコントロールネットを紹介したいと思います。









【Amazon.co.jp 限定】Inner Garden 可作品集 ILLUSTRATION MAKING & VISUAL BOOK(特典:デジタル壁紙)
ASIN:4798189235
